A Practical Guide to Fine-Tuning LLMs: From Full Training to LoRA
Understand how LLM fine-tuning works, when to use it, and how to choose between full fine-tuning, LoRA, soft prompts, and other PEFT methods.

Fine-tuning is how you take a general-purpose LLM and make it yours. But “fine-tuning” is an umbrella term covering wildly different approaches — from retraining every parameter to learning a handful of virtual tokens. Choosing the wrong method means burning compute for marginal gains.
This post breaks down the options and when to use each one.
The Problem
Base foundation models are impressive but generic. They don’t know your domain vocabulary, your output format requirements, or your organization’s tone. Prompt engineering gets you far, RAG adds knowledge — but sometimes you need the model itself to behave differently.
The challenge: fine-tuning methods range from trivial to massive in cost and complexity. Without understanding what each method actually does inside the model, it’s hard to pick the right one.
The Solution
Map each fine-tuning method to where it intervenes in the transformer architecture, then choose based on your quality requirements, compute budget, and how different your target behavior is from the base model.
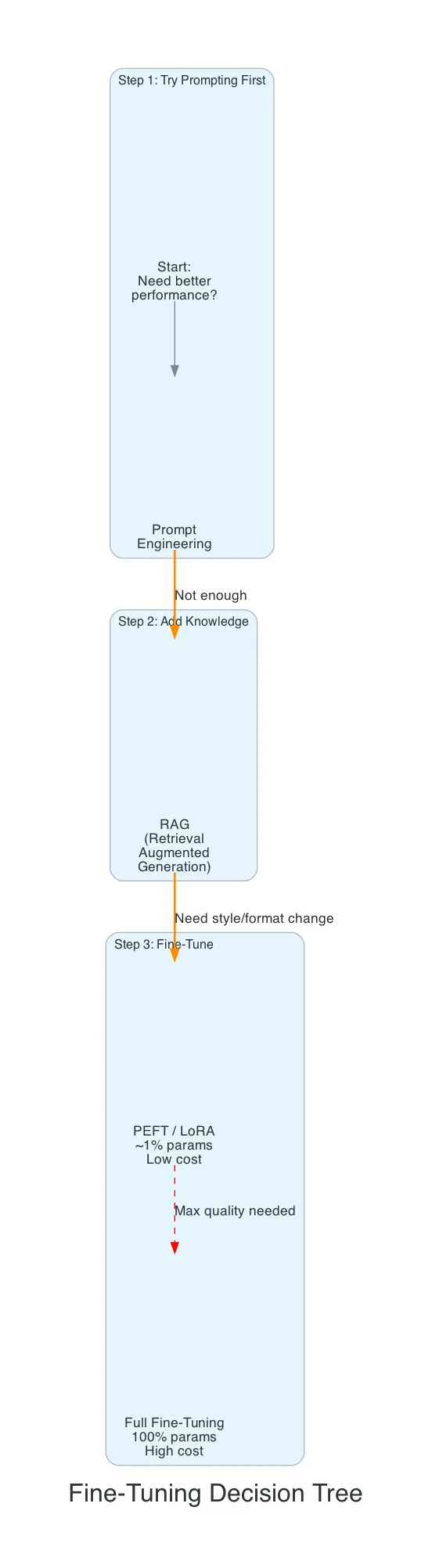
The decision ladder:
- Prompt engineering — just ask the model better. Zero cost. Try this first.
- RAG — give the model reference documents at inference time. Moderate effort, no training.
- PEFT (LoRA) — retrain ~1% of the model. Low cost, high impact. Default choice.
- Full fine-tuning — retrain everything. Maximum quality, maximum cost.
How It Works
Inside a Transformer
Every transformer-based LLM is built from repeated layers with two main components:
- Self-Attention — figures out which tokens are relevant to each other
- Feedforward Network (FFN) — processes what that information means
The FFN is deceptively simple: expand the representation to a larger dimension, apply an activation function, compress it back down. These layers store most of the model’s factual knowledge and account for roughly two-thirds of its parameters.
Each layer repeats: Attention → FFN → Attention → FFN, stacked dozens or hundreds of times.
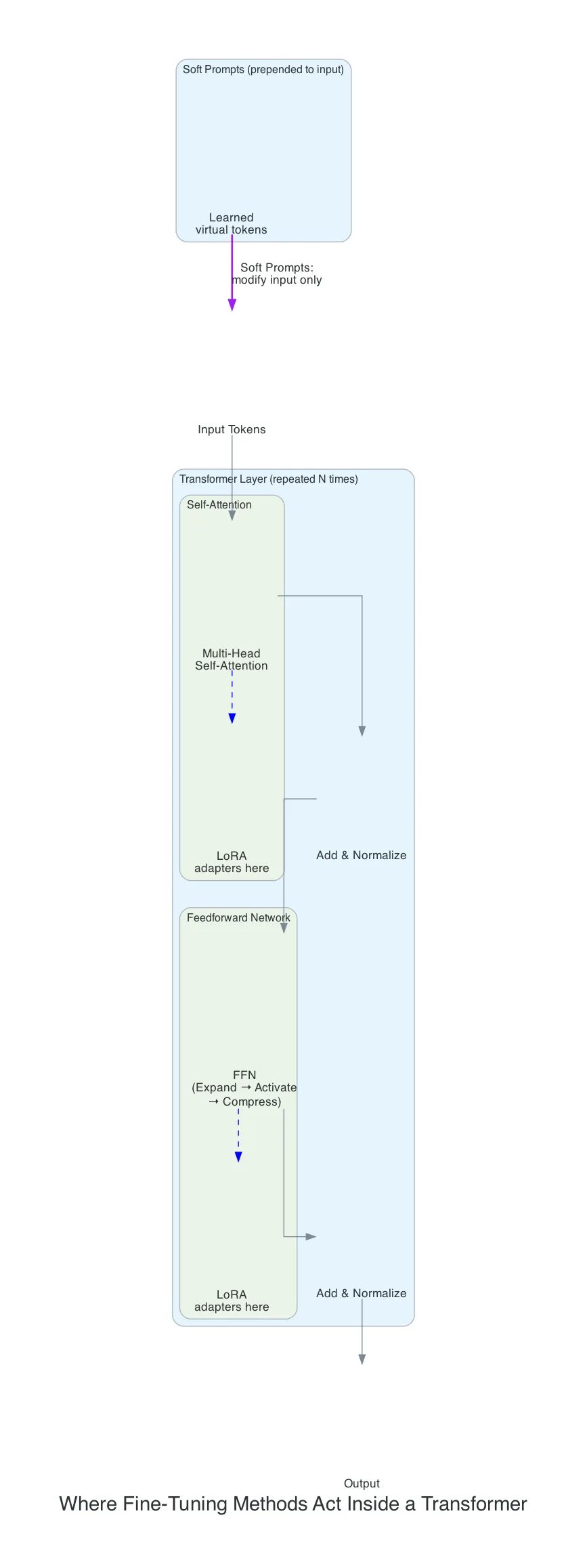
Different fine-tuning methods intervene at different points in this pipeline.
Fine-Tuning Flavors
Think of it this way:
- Pre-training = general education (school, university)
- Fine-tuning = job-specific training (learning your company’s processes)
| Method | What it does |
|---|---|
| Supervised Fine-Tuning (SFT) | Train on input/output pairs — the most common starting point |
| RLHF | Humans rank outputs, model learns to prefer higher-ranked ones |
| Instruction Tuning | SFT subset focused on instruction-following — turns base models into chat models |
Typical pipeline: Base Model → SFT → RLHF → Final Model
The “What” vs the “How”
A common source of confusion: people compare instruction fine-tuning, LoRA, and soft prompts as if they’re all alternatives. They’re not — they answer different questions.
- Instruction fine-tuning = the what — the type of training data you use (instruction/response pairs)
- LoRA, soft prompts, full fine-tuning = the how — the technical method you use to modify the model
You can do instruction fine-tuning with LoRA. Or with full fine-tuning. Or with soft prompts. The training data and the training method are independent choices.
| What it is | Analogy | |
|---|---|---|
| Instruction fine-tuning | Training data format | The textbook |
| LoRA | Training method — modifies model internals | Teaching new skills |
| Soft prompts | Training method — modifies model input | Writing a cheat sheet |
In practice, instruction fine-tuning + LoRA is what most people mean when they say “fine-tuning” today.
Full Fine-Tuning (PFT) vs PEFT
This is the fundamental fork in the road.
Full fine-tuning unfreezes every parameter. Maximum flexibility, but a 7B model needs 100+ GB VRAM for training.
PEFT freezes the original model, trains only a small number of new parameters. Gets surprisingly close to full fine-tuning quality.
| Full Fine-Tuning (PFT) | PEFT | |
|---|---|---|
| Params trained | 100% | ~0.1–2% |
| Memory | Very high | 10-100x less |
| Quality | Best possible | 90-99% of PFT |
| Training speed | Slow | Fast |
| Catastrophic forgetting risk | Higher | Lower (original weights frozen) |
| Multi-task | Separate model copies | Swap small adapters on one base model |
LoRA (Low-Rank Adaptation)
The most popular PEFT method. Injects small trainable matrices alongside existing attention layers. The original weights stay frozen; LoRA matrices modify how information flows through the model.
Think of it as teaching someone new skills — the model internalizes new capabilities.
- Trains ~0.1-1% of total parameters
- Produces small adapter files (MBs, not GBs)
- Multiple adapters can be swapped on a single base model
QLoRA goes further: quantizes the base model to 4-bit, letting you fine-tune a 65B model on a single GPU.
Soft Prompts (Prompt Tuning)
Learns virtual tokens prepended to your input. The model itself is completely frozen.
Think of it as giving someone a really good briefing — they don’t change, they just get better instructions.
[learned token 1][learned token 2]...[learned token N] + your actual input- Trains only thousands of parameters (vs millions for LoRA)
- Adapter size in KBs
- Limited for complex generation — the change is surface-level
PEFT Methods Compared
| Method | How it works | Best for |
|---|---|---|
| LoRA | Adds trainable matrices to attention layers | General-purpose fine-tuning |
| QLoRA | LoRA + quantized base model | Large models on limited hardware |
| Prefix Tuning | Learns virtual tokens at every layer | Generation tasks |
| Adapters | Inserts small trainable layers between frozen layers | Multi-task setups |
| Soft Prompts | Learns input embeddings only | Simple classification |
The key difference: soft prompts change what the model sees (input). LoRA changes how the model thinks (internal processing).
Choosing Your Method
| Situation | Method |
|---|---|
| Most use cases, best cost/quality tradeoff | LoRA |
| Large model, limited GPU budget | QLoRA |
| Simple classification or routing | Soft Prompts |
| Maximum quality, unlimited budget | Full Fine-Tuning |
| Multiple tasks on one base model | LoRA (swap adapters) |
On AWS
- Amazon Bedrock Custom Models — fine-tune foundation models without managing infrastructure
- Amazon SageMaker — full control, bring your own training scripts, Hugging Face PEFT library
- AWS Trainium / Inferentia — cost-effective custom silicon for training and inference at scale
For most teams, Bedrock’s managed fine-tuning is the path of least resistance. SageMaker when you need full control over hyperparameters or cutting-edge PEFT techniques.
What I Learned
- Separate the “what” from the “how” — instruction fine-tuning is the training data, LoRA is the training method. They’re independent choices, not alternatives
- LoRA is the default answer — it covers the vast majority of use cases at a fraction of the cost of full fine-tuning
- Don’t fine-tune first — prompt engineering and RAG solve most problems without any training
- FFN layers are the knowledge store — understanding where knowledge lives in a transformer helps explain why different methods work differently
- Soft prompts are niche — interesting for minimal adapters, but LoRA’s quality advantage makes it the practical choice
- QLoRA is a game-changer for access — fine-tuning large models on consumer hardware was impossible before it
What’s Next
- Hands-on: fine-tune a model with LoRA on SageMaker and measure quality vs base
- Compare Bedrock custom models vs SageMaker PEFT for the same use case
- Explore MoE (Mixture of Experts) as a scaling approach for fine-tuned models
Related Posts
TFLOPS: The GPU Metric Every AI Engineer Should Understand
What TFLOPS actually measures, why FP16 matters for LLMs, and why the most important GPU bottleneck for inference isn't compute at all.
AIFine-Tuning Mistral with Transformers and Serving with vLLM on AWS
End-to-end guide: fine-tune Mistral models with LoRA using Hugging Face Transformers, then deploy at scale with vLLM on AWS — from training to production serving on SageMaker, ECS, or Bedrock.
AIHow LLMs Learn to Behave: RLHF, Reward Models, and the Alignment Problem
A practical walkthrough of how large language models are aligned with human values — from collecting feedback to PPO optimization and the reward hacking pitfalls.