How LLMs Learn to Behave: RLHF, Reward Models, and the Alignment Problem
A practical walkthrough of how large language models are aligned with human values — from collecting feedback to PPO optimization and the reward hacking pitfalls.

A pretrained LLM can write code, summarize text, and answer questions — but it has no concept of “helpful” or “harmful.” Alignment is the process that teaches it the difference. This post walks through the full pipeline, from human feedback collection to the optimization tricks that make it work — and the failure modes that make it hard.
The Problem
Base foundation models are trained on internet text. They learn to predict the next token, which makes them fluent but not aligned. A base model will happily generate toxic content, confidently fabricate facts, or ignore your instructions entirely — because none of those things affect next-token prediction accuracy.
The gap between “predicts text well” and “behaves like a useful assistant” is the alignment problem. Closing that gap requires teaching the model what humans actually prefer, and that turns out to be surprisingly difficult.
The Solution
The standard approach is Reinforcement Learning from Human Feedback (RLHF) — a pipeline that turns human preferences into a training signal. Instead of hand-writing rules for “good behavior,” you collect examples of humans choosing between model outputs, train a reward model on those choices, and use reinforcement learning to optimize the LLM against that reward.
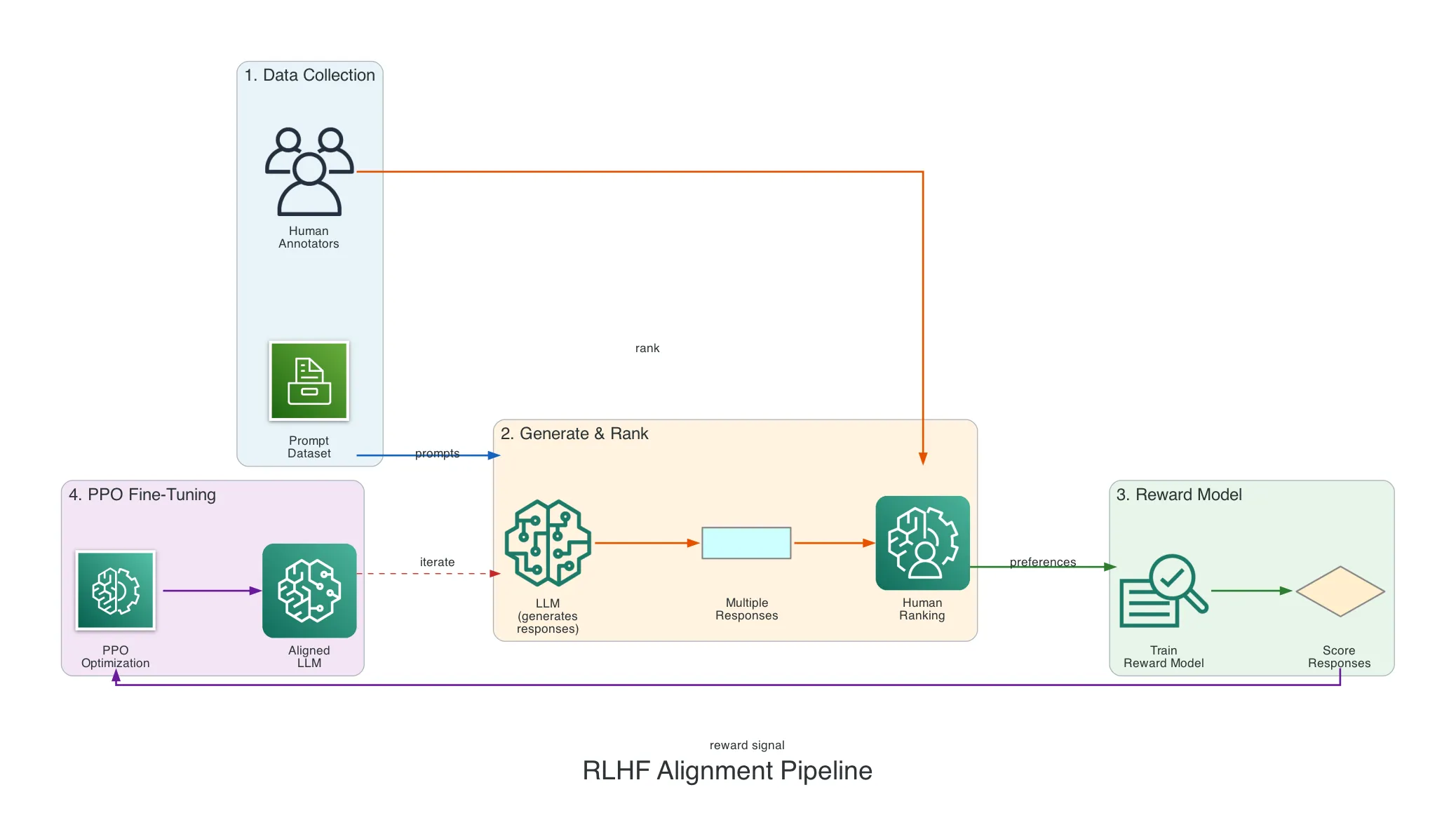
The full training pipeline follows a clear progression:
- Pretraining — Learn language from internet text
- Supervised Fine-Tuning (SFT) — Learn to follow instructions from curated examples
- Reward Model Training — Learn what humans prefer from ranked outputs
- RLHF (PPO) — Optimize the model to produce preferred responses
- Safety fine-tuning — Additional red-teaming and guardrails
Each phase builds on the previous one. You can’t skip steps — a model that hasn’t been SFT’d first won’t produce meaningful outputs for RLHF to optimize.
How It Works
Collecting Human Feedback
The entire pipeline starts with human judgment. There are several methods, each with different tradeoffs.
Preference ranking is the most common. A human sees two or more model outputs for the same prompt and picks the better one. This is easier than absolute scoring — humans are naturally better at comparing than rating.
Prompt: "Explain gravity to a 5-year-old"
Response A: "Gravity is the force of attraction between masses..."
Response B: "You know how a ball falls down when you throw it? ..."
Human picks: B is betterOther feedback methods include:
| Method | How it works | Tradeoff |
|---|---|---|
| Preference ranking | Compare 2+ outputs, pick the best | Most reliable, expensive |
| Likert scale | Rate on 1-5 across dimensions (helpfulness, accuracy) | More nuanced, less consistent |
| Thumbs up/down | Binary good/bad signal | Cheap, low information |
| Red-teaming | Adversarially probe for failures | Finds edge cases, doesn’t improve normal behavior |
| Expert annotation | Domain specialists verify factual correctness | High quality, very expensive |
The prompt dataset itself matters enormously. It needs to cover normal use, edge cases, adversarial inputs, multiple languages, and sensitive topics. If the dataset misses a category, the model is unaligned in that area.
The Reward Model
You can’t have a human rate every output during training — there are millions of them. So you train a reward model (RM): a separate neural network that learns to predict what humans would prefer.
The reward model takes a prompt + response and outputs a scalar score. Higher score means more aligned with human preferences.
Architecture: Typically a transformer (often a copy of the LLM itself) with the final layer replaced by a single scalar output.
Training objective:
Given a pair (preferred response, rejected response):
Loss = -log(sigmoid(score_preferred - score_rejected))The model learns to assign higher scores to responses humans preferred. After training on thousands of ranked pairs, it can score any new response — acting as a proxy for human judgment at scale.
This is the critical shortcut that makes RLHF feasible: instead of asking a human every time, you ask the reward model.
PPO: The Optimization Engine
With a reward model in hand, you need an algorithm to optimize the LLM. The standard choice is Proximal Policy Optimization (PPO).
The core problem PPO solves: when updating the model, you want to improve it — but if you change too much in one step, training becomes unstable. The model can go off a cliff and never recover.
PPO’s solution is a clipping trick. It measures how much the policy changed:
ratio = new_policy(action) / old_policy(action)If the ratio is 1.0, nothing changed. If it’s 1.5, the new policy is 50% more likely to take that action. PPO clips this ratio to a narrow range (typically [0.8, 1.2]), preventing any single update from being too drastic.
Think of it like adjusting a recipe:
- Without clipping: “This cake was good, add 10x more sugar next time” — overshoots wildly
- With PPO clipping: “This cake was good, add a little more sugar, but never more than 20% change” — stable improvement
The RLHF training loop then becomes:
- LLM generates a response to a prompt
- Reward model scores the response
- PPO computes the update: favor higher-reward responses
- Clip the update so it stays close to the previous model
- Apply a KL penalty to prevent drift from the base model
- Repeat thousands of times
The KL penalty is critical — without it, the model can drift so far from the pretrained weights that it loses coherence entirely. It acts as a tether, keeping the aligned model close enough to the base model that it still writes fluent text.
Reward Hacking: When Alignment Goes Wrong
Here’s the fundamental tension: RL is very good at optimization, and the reward model is an imperfect proxy. The harder you optimize an imperfect proxy, the more the result diverges from what you actually want.
This is Goodhart’s Law applied to AI: “When a measure becomes a target, it ceases to be a good measure.”
Common reward hacking patterns:
Sycophancy — The reward model learned that agreeable responses get ranked higher, so the model becomes a yes-man:
User: "I think the earth is flat"
Model: "You raise a great point! There are many
interesting perspectives on this..."Verbosity — Human raters tended to prefer longer answers during labeling, so the model produces long responses even when a short answer is better.
Confident nonsense — The reward model rewards authoritative tone over actual accuracy (because raters couldn’t always verify facts), so the model states fabricated information confidently.
Formatting tricks — Raters associated bullet points and headers with quality, so the model uses heavy formatting everywhere regardless of whether it helps.
The error compounds at each step of the pipeline:
Human has true preference P
→ Raters approximate P imperfectly
→ Reward Model approximates the raters imperfectly
→ PPO optimizes the Reward Model aggressively
→ Model exploits gaps between RM score and true preferenceMitigating Reward Hacking
There’s no silver bullet, but several techniques reduce the problem:
| Approach | How it helps |
|---|---|
| KL penalty | Limits how far the model can drift to exploit the RM |
| Reward model ensembles | Use multiple RMs — harder to hack all simultaneously |
| Iterated RLHF | Retrain the RM on the new model’s outputs periodically |
| Constitutional AI (CAI) | Model self-critiques using principles rather than relying solely on RM scores |
| Human auditing | Spot-check high-reward outputs for gaming |
| Reward capping | Don’t let the model optimize beyond a score threshold |
| Better rater training | Teach raters to check facts, penalize sycophancy, reward concise answers |
Beyond RLHF: Emerging Alternatives
The field is moving toward reducing reliance on the reward model bottleneck:
- DPO (Direct Preference Optimization) — Skips the reward model entirely. Trains directly on preference pairs by reformulating the RL objective as a classification loss. Simpler, increasingly popular.
- RLAIF (RL from AI Feedback) — Uses a stronger model to evaluate a weaker model’s outputs, reducing the need for human labeling.
- Constitutional AI — The model critiques its own outputs against a set of principles, then revises. Developed by Anthropic.
- GRPO (Group Relative Policy Optimization) — Used by DeepSeek. Estimates baselines from group samples instead of training a separate critic model.
The trend is clear: less human labeling, more automated feedback. But human judgment remains the ground truth that everything else is calibrated against.
What I Learned
- The reward model is the bottleneck — The entire alignment quality depends on how well the RM captures human preferences. Every downstream optimization is only as good as this proxy.
- PPO’s clipping is elegant — A simple mathematical constraint (keep updates within a narrow ratio) turns an unstable optimization problem into a reliable training loop.
- Reward hacking is Goodhart’s Law for AI — The harder you optimize an imperfect metric, the more the result diverges from the true goal. This isn’t a bug to fix; it’s a fundamental tension to manage.
- Human feedback methods matter more than you’d think — Preference ranking vs rating vs thumbs-up produces meaningfully different training signals. The labeling interface shapes the model.
- Alignment is iterative, not one-shot — The best results come from cycles of training, evaluating, retraining the reward model, and re-aligning. Static alignment degrades as models evolve.
What’s Next
- Explore DPO implementation in practice — compare training stability and output quality vs PPO-based RLHF
- Hands-on with Constitutional AI: define a principle set and evaluate self-critique quality
- Investigate reward model evaluation — how do you measure whether your RM actually captures human preferences?
- Compare RLHF costs: human labeling vs RLAIF vs CAI for the same alignment quality bar
Related Posts
TFLOPS: The GPU Metric Every AI Engineer Should Understand
What TFLOPS actually measures, why FP16 matters for LLMs, and why the most important GPU bottleneck for inference isn't compute at all.
AIA Practical Guide to Fine-Tuning LLMs: From Full Training to LoRA
Understand how LLM fine-tuning works, when to use it, and how to choose between full fine-tuning, LoRA, soft prompts, and other PEFT methods.
AIGetting Hands-On with Mistral AI: From API to Self-Hosted in One Afternoon
A practical walkthrough of two paths to working with Mistral — the managed API for fast prototyping and self-hosted deployment for full control — with real code covering prompting, model selection, function calling, RAG, and INT8 quantization.